100 Movies in the Cinema in 1 Year
After reading this blog post at the end of January I decided that watching at least 100 movies in the cinema in a year was the kind of challenge I could get behind. Last year’s challenge to get fit and healthy was fairly successful and seemed like much harder work than going to the cinema a few times could ever be. After all, 100 movies a year is less than 2 a week, so it must be easy, right?
Unfortunately I started this project late, so at the time of reading the article and deciding to go ahead with it I was four weeks into the year and had only seen three films at the cinema. This is not the kind of progress needed for this challenge! So, I got myself a cineworld unlimited card and hit the cinema hard, aiming to get through February and be caught up to where I should be by the end of the month.
Of course, being a massive data geek I have been recording everything, making a note of every movie I have seen this year so far, which means I’m amassing a fairly large amount of data on my movie watching habits, which can mean only one thing. Crappy Excel Graphs! I’ll be posting some throughout the year to mark how the challenge is going, and the first lot are here.
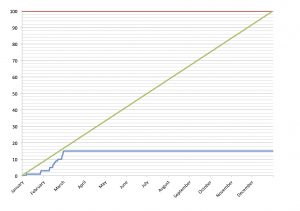
The first shows the number of movies seen in total for each day of the year against the number of movies I would need to see in order to hit the target of 100 by December 31st. As you can see, the late start in January did me no favours, but by the end of February I’ve almost caught up to be where I need to be.
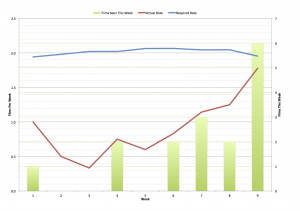
The second crappy excel graph shows the movie viewing rate (the number of movies seen divided by the number of weeks elapsed) against the target rate, along with the actual number of movies watched that week. It’s clear to see that January was a wash out, but that February was excellent and helped to bring the target rate down below 2 movies a week.
So, that’s where we’re at. It’s March and I’ve seen 16 films at the cinema, at an average cost of £3.18 per movie. I’m well on the way to 100 and I’ll keep you updated with more crappy excel graphs and rubbish averages along the way…