Along with Matthew Williams and Chris Gwilliams I’m helping to organise the Cardiff edition of the Foursquare global hackathon this weekend. I’m hoping it’ll be a pretty good event. Signup’s are looking pretty positive and I’m hopeful that we’ll get some decent apps being created.
The organising is actually quite fun, but it is remarkable how much there is to do and remember. Thankfully the School of Computer Science & Informatics are being very supportive and allowing us to host it there, which makes things easier. I’ll be posting here throughout the event (and afterwards).
Moving on from my fun with getting django + twitter + oauth to play nicely, it’s now time to start writing a web app that uses foursquare as the authentication/login method. As part of this, I need a basic django framework for doing authentication with foursquare. This may be useful to someone else at some point (including me when I forget in three months time how I did things), so I’ve written up the details and added the code to github.
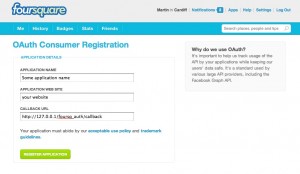
Firstly, you need to register an application with Foursquare to get your Client ID and Client Secret. You can enter any name and website you want, but the callback url needs to be our local development machine (assuming that’s where you’re doing the development), and to be the callback url that we’re going to specify in a minute:
The more observant will notice that the callback url is currently http://127.0.0.1/foursq_auth/callback/, but that the django web server actually runs on port 8000, so the url really needs to be http://127.0.0.1:8000/foursq_auth/callback/. Unfortunately the form validation doesn’t allow you to use a ‘:’ in your callback url. However, once the consumer is registered you can edit the callback url, and the form for that doesn’t validate the url (or does but doesn’t moan about the colon). Eventually, you are looking for the consumer to be registered with a callback url like this:
Once that is registered, we can get on with writing the code. The basic premise is pretty simple, we need just five urls in our django app, five views to go with them, and two basic html pages, one for login, and one to show we are logged in. Assuming you have a django project started (for reference the one I’m using here is called ‘Dj4sq’) we can start by creating our foursquare app:
django-admin.py startapp foursq_auth
We then want to edit urls.py for our main django project to allow the new app to handle its own views:
and create and edit a file urls.py in the foursq_auth app with the five views we want:
urlpatterns = patterns('foursq_auth.views', # main page redirects to start or login url(r'^$', view=main, name='main'), # receive OAuth token from 4sq url(r'^callback/$', view=callback, name='oauth_return'), # logout from the app url(r'^logout/$', view=unauth, name='oauth_unauth'), # authenticate with 4sq using OAuth url(r'^auth/$', view=auth, name='oauth_auth'), # main page once logged in url(r'^done/$', view=done, name='oauth_done'), )
We then need our two basic html pages login.html and done.html:
The second, ‘auth’, is the first step in our authentication process, requesting an authorisation code from foursquare and redirecting the user to the page to authorise our app:
defauth( request ): # build the url to request params ={'client_id': CLIENT_ID, 'response_type':'code', 'redirect_uri': redirect_url } data = urllib.urlencode( params ) # redirect the user to the url to confirm access for the app return HttpResponseRedirect('%s?%s'%(request_token_url, data))
If the user accepts our app, they’ll be re-directed to our callback url, and an authorisation code will be passed back as one of the parameters of the url, so the next view, ‘callback’ needs to deal with this. It then needs to post a request to foursquare with the authorisation code in order to receive the access_token for the user:
# get the code returned from foursquare code = request.GET.get('code')
# build the url to request the access_token params ={'client_id': CLIENT_ID, 'client_secret': CLIENT_SECRET, 'grant_type':'authorization_code', 'redirect_uri': redirect_url, 'code': code} data = urllib.urlencode( params ) req = urllib2.Request( access_token_url, data )
# store the access_token for later use request.session['access_token']= access_token
# redirect the user to show we're done return HttpResponseRedirect(reverse('oauth_done'))
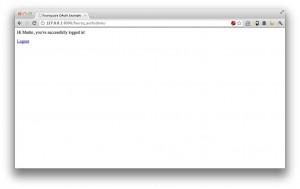
If we’ve got the access token, we’re all set. From now on we can make any calls to the Foursquare API that require authorisation, as long as we supply this token as a parameter to the request named ‘oauth_token’. To prove that we’re logged in, we’ll re-direct the user at the end of the callback to a ‘done’ page, which will display some user details:
defdone( request ): # get the access_token access_token = request.session.get('access_token')
# request user details from foursquare params ={'oauth_token': access_token } data = urllib.urlencode( params ) url ='https://api.foursquare.com/v2/users/self' full_url = url +'?'+ data print full_url response = urllib2.urlopen( full_url ) response = response.read() user = json.loads( response )['response']['user'] name = user['firstName']
# show the page with the user's name to show they've logged in return render_to_response('foursq_auth/done.html',{'name':name})
And with that, we’re all done. We can fire up the django server with:
python manage.py runserver
open our browser to 127.0.0.1:8000/foursq_auth/ and go through the login process:
And that’s that - A Django web app doing OAuth authentication with Foursquare. The full code is up on github if you want to take a closer look.
It’s the last full day at the festival and we wake up even later than the day before. It’s so late we decide to skip breakfast, and as it’s time for lunch we’ll head out for curry. A quick curry and rice and we’re up and running for the day once more. The shows today don’t start until later on, so we have a bit of a walk around, grab a coffee and cake, then once more split, as Lisa decides to go back to the flat briefly while I head to pub. I sit out of the rain doing the crossword, have a pint and await Lisa’s return. She arrives, we finish the crossword, and head off to the show. The first show of the day is Ruby Wax in her one woman play (that’s got two women in it): Losing It. It’s a fantastic and honest play about mental illness, really well done, with some laughs and a lot of truth.
Following the show we take a walk over to near Arthur’s seat, then back towards town for the last show of our festival. On the way we find a really ace pub that I think will be my local when I make it to Edinburgh full time. We have a quick pint, then go to the Queens Hall for Henry Rollins. The man is amazing, he gets up on stage and just talks for the evening, and everything he says is amusing or thoughtful and brilliant. He’s basically just telling us what he’s done for the last year, with some old road stories thrown in for good measure, but he’s such a great speaker its one of the highlights of the week. I think most academics I’ve seen talk could learn hugely from the passion and thought he puts into telling stories.
Post show we head back to the pub for a couple of pints, then grab a chinese takeaway and head back to the flat. With that, we’re done. Wasted, destroyed. Great week.
Shows: 2
Pints: A few
Chinese Food: some
Aging rock stars: one
Wednesday we wake up later than intended, so miss the planned start to the day at the Shakespeare breakfast. In all, it’s a very slow start to the day, the pace of the previous few days is beginning to get to us. We head off for a walk and a bagel to wake up, and I get butter all over my face from a very lovely, but very buttery and bacon filled bagel. After soaking up a bit of sunshine in the cafe we head down to town for our first show, an adaptation of Secret Window, Secret Garden. The venue is at C soco, which is the massive hole in the ground in the Old Town where the fire was a few years back, the one that took out the original Gilded Balloon and the School of Informatics’ AI department. The venue itself is in one of the buildings left standing on the site, which may well have been part of the University from looking at it, and the specific venue we’re in is right at the top. I estimate we climbed about 4000ft to reach it, but I may be wrong.
The play itself is nicely done, they’ve cut the story down to the minimum of necessary elements to cover everything in the plot while still bringing the play in at an hour, and the acting is pretty solid, if not stellar. The lead character is by far the best actor of the lot, doing a very good job at playing the role of the author losing his mind. They stick to the plot of the book too, rather than the film, which is pleasing. The guy playing John Shooter troubles me a little, and it’s not until afterwards that I realise it’s because he looks, sounds, and acts very much like someone at COMSC.
We’ve got a gap in the afternoon, so we head down to one of the ‘attractions’ of Edinburgh we haven’t visited yet, the Botanic Gardens. It’s a fair enough walk, mostly downhill. We cause a problem in the cafe at the east gate by attempting to buy things with a twenty pound note, the horror. They have nowhere near enough change, but there’s a solution to the problem if they let me off the odd 35p and I just pay them £5. They agree, so I effectively steal 35p of goods off a registered charity. In your face, plants.
It’s a nice place for a wander round, as lovely gardens tend to be. We decide to put up the cash to go into the hothouses, being as we’ve walked all the way down there. Surprisingly, they’re hot, and full of plants. I can’t get the Jurassic Park theme out of my head as I walk around, the whole place is reminiscent of the science labs in the sequels that have been taken over by plants, there’s a nice bit of ageing decay to them. Very few dinosaurs though, luckily.
After the botanic gardens we head to a pub down the road for a pretty decent dinner and a couple of pints, then make long trek back up the hill and into town. Lisa wants to head back to the flat, but I can’t be bothered, so I head down to the Brewdog bar on Cowgate to wait for her. I’m quite a fan of Brewdog beer, and it’s a nice bar (if a bit small), serving some very lovely booze. While I’m stood at the bar reading the paper it begins to absolutely piss it down with rain, so by the time Lisa gets back into town she is soaked through once more. As ever, the theory ‘go to the pub, not home’ has paid off.
We head up to the Assembly Hall to meet Lisa’s colleague and his wife for a pint before Sarah Millican. We have a nice chat for half an hour, then get into the longest queue yet for a show. We end up with seats up on the balcony, but it’s a fine venue that seems to hold a lot of people without feeling massive, so the view is pretty good and you still feel pretty close to the stage. Sarah Millican is good, but the show seems like a collection of one liners and jokes rather than a coherent whole. Despite that it’s hilariously funny, and a good time is had by both of us. I steal two badges at the end of the show, making it both a registered charity and a comedian that I’ve effectively cheated in one day.
Following the show we head down to the Conference Centre for an Amnesty gig. I thought the queue for the Millican show was big, but the queue at the EICC was huge, snaking all the way round to the back of the building and out into the street. I have a minor altercation with some old ladies in the queue who are queue jumping, and refuse to move when I inform them of the fact. Another chap also tries to let them know, but they ignore him too. So we talk loudly about the older generation just thinking they can do what they want, and how old people have no manners anymore and don’t understand about how being British means we treat each other decently and are polite and so on. I’m half convinced we quite embarrassed the one old lady, but her friend was made of sterner stuff. The old ladies have annoyed me massively, but it’s wearing off by the time we get into the venue, until I discover that bottles of beer at the bar are £3.80 each, which almost makes things even worse. Luckily the show is laugh balls funny. It’s basically ten minutes sets from a whole mix of comedians that we wouldn’t have otherwise seen, with a large number of laughs coming from making the signers at the side of the stage make inappropriate gestures. It’s a great gig, with performances from Mark Watson, Ed Byrne, Russell Kane, Jenny Eclair, David O’Doherty, Holly Walsh and Roisin Conaty. Once more we both enjoy it, laugh too much, and leave happy. We head home satisfied for the evening.
Shows: 3
Pints: God knows
Queues: Massive
Old ladies: Three (irritating and rude)
Success today as we start the day with a run round the meadows, despite all the beer yesterday. A ‘debate’ which I lose ends in us also running around the links and up towards Warrender Park Crescent. The flat I stayed in during my second stint in Edinburgh for the MSc was there, so it was nice to be running around the old stomping ground.
After the run I bump into another Shrewsbury Town fan outside tesco’s. I knew there were more than one of us. We buy picnic material from the shop, then despite the weather forecast promising rain we decide to head up Arthur’s seat. What a stupid idea. The whole time we are out of the flat it absolutely chucks it down. A bit of rain isn’t enough to stop us though, we go up the hill anyway, stand under a tree and eat our cheese sandwiches, then go home. A proper british picnic.
We manage to dry off in the flat, grab a cup of tea, then head over to The Stand comedy club for the afternoons shows. The Stand is a tiny venue, but was very full for both shows this afternoon, so there was a great atmosphere in the place. First up was Simon Munnery, with his show “Hats off for the 101ers (and other material)”, a show that started with a punk rock musical about the designers of the 101 airship, which tells you a fair amount about the type of show it was. Simon is a comedian I’ve heard a lot about but never seen, he was ace, really really funny, with some really weird material, but all of it brilliant. Quite odd, but brilliant. Following Simon was Stewart Lee with his show “Flickwerk”. I love Stewart Lee with a passion bordering on obsessive, he’s absolutely brilliant. The show (that wasn’t really a show, just work in progress) had me in stitches all the way through. I was genuinely concerned that I may have a heart attack at points during the show. Afterwards I hung around to buy a CD off Stewart and tell him I thought it was really good. Which it was. Unfortunately I’d forgotten to tell Lisa I was going to do that, so she headed straight outside and stood in the rain waiting for me. Oops.
We headed off for an Italian, blowing the budget at quite a nice posh restaurant on a lot of food and red wine. I decided during my meal that my comedy nerves had been destroyed totally by the show and I would never laugh at anything ever again. Luckily I realised later that it wasn’t true.
The last show of the evening was at the Edinburgh College of Art: “Tales from Edgar Allan Poe”. Another amateur production, this was exceedingly odd. The audience all stood around the edge of the room while various Poe poems and stories were acted out by a cast who, when not involved in a tale, stood around in creepy masks. The performances were all really good, and we left at almost midnight feeling pretty damn creeped out.
Day two began with the best intentions - I woke up early, fully intending to go for a run around the meadows. It only took about thirty seconds of being awake for me to realise that wasn’t going to happen, so I went back to sleep for another hour. By about 8.30 the waking up was really beginning to take hold, so we relented and got up.
Usual morning operations completed (including Lisa having to conclude delicate negotiations with reception for the use of a hairdryer), we headed out into town. The first show of the day was up at C-too, at St Columbus by the Castle, so we had our first experience of trying to get anywhere near the Royal Mile at festival time. It appears that at festival time the Royal Mile essentially becomes a solid mass of people. Some of them want you to come to their show. Some of them want you to go to someone else’s show. Many of them want to give you a leaflet. Some of them just want to perform a show for you in the street. I hate crowds. I hate people walking slowly. It was not a happy start to the day.
Luckily we got to the venue in time to have a sit down in the church garden outside the venue and have a coffee. The weather again was glorious, so we were able to sit in the early morning sun and soak up the warmth and admire the views over south Edinburgh. Again, writing this now, I think I probably should have taken some photos, but I didn’t. Just go there and see it yourself, it’s much better.
The show we were going to see was “Love’s Labour’s Lost”. To be honest, once we got into the venue I was a bit worried as it seemed to be being performed by young people. I have strong views about ‘young people’, and those views seem to be getting worse as I get older. Luckily though, these young people were of the talented variety, and put on a pretty good show. I’d never seen or read the play before, so can’t compare it to the source, but the production was well done and well acted, and they’d gone down the current trendy route of inserting modern songs and cultural references into a shakespeare play, but carried it off well. It was again a thoroughly enjoyable hour, and it’s always nice to kick the day off with a bit of culture.
Following the show we wandered around the old town for a bit in search of a postbox, then sought out lunch. We then headed down to the BBC pop-up venue on Potterrow, where our next show was. This was actually what I was calling ‘Richard Herring Day’, as we had two shows from the man himself in one day. First up was a ‘festival special’ recording of his Radio 4 show ‘Richard Herring’s Objective’. I liked the BBC venue because they seemed not to believe in queues, instead giving you a numbered sticker on arrival then calling you in to the venue by number when it was time for the show. This means the people that get there first still get the best seats, but also get to wander around, go get drinks, look at other things etc, rather than standing around in a queue. Unfortunately as we’d decided to call at the Pear Tree for a swift pint before the show we were somewhere at the back of the virtual queue. We still got in though (free BBC shows are over-sold to make sure there’s a full audience to make it sound good on the radio) and were entertained by Mr Herring and his guests: Emma Kennedy and Susan Calman. The show was funny, but it dragged in parts - and to be honest the unscripted moments were probably the funniest moments, particularly the parts that went wrong and had to be re-recorded. The casual racism against the Scots was highly amusing and brave given that it was performed in the middle of Edinburgh.
We had a couple of hours free then before the next show, so did a bit more walking around the city, called for a couple of drinks, got some dinner, then headed down to Bristo Square. As we stood in the queue outside the venue drinking some weird festival ale we got chatting to the man in the queue next to us, who was an American. A real live foreigner and everything. Strangely enough, he was only in Edinburgh for a couple of days and was heading to Cardiff afterwards to go sightseeing - apparently the appeal of Doctor Who and Torchwood is greater than we’d imagined, as he was quite a fan and was visiting solely because of those shows. We gave him a bit of travel advice, hopefully he survived the visit.
The show we were queuing for was Richard Herring again, this time for his main show “What is Love Anyway?”. It’s getting a bit boring to say, but this was yet another brilliant hour of comedy. Very honest and at times emotional comedy, but full of laughs and well worth a watch. Unsurprisingly the subject of the show was love, and how us humans use and abuse it, how we deal with it, and an attempt to discover what it really is. Loved the show.
After the show we headed over to Pleasance Courtyard to meet up with one of Lisa’s colleagues who was also up in Edinburgh. We had a couple of drinks, swapped some show reviews and tips and had a bit of a chat. The place was swarming in comedians, some well known faces being left (relatively) alone, some less well known trying to convince people to come see their shows. After a while we all headed back towards the flats (they were staying in the same place), but me and Lisa decided there was time for another drink, so headed off to the pub.
Shows: 3
Pints: 8
Meals: too many noodles
Herring: twice
Our first show was Dave Gorman at Assembly at the George Square Lecture Theatre, so after checking in we headed straight over there. We sat in the sun on the steps outside the venue and supped a couple of pints of Deuchars. We shouldn’t have bothered, it was served so cold you couldn’t taste anything, although maybe that was a blessing seeing as it came from a bar inside a shipping container and was served in a plastic cup. If you’re going to get beer in you at the festival there is very little room for beer snobbery. Luckily I’m not a beer snob, so I got some in me.
Down the street a little way some street entertainers were doing a show with tightrope walking and juggling and unicycling, amusing a crowd that had gathered in the corner of the square to watch. Across the road the sounds of other shows spilled out of tents in the Square. It was a nice introduction to the atmosphere of the festival.
While we hadn’t planned on it, we found ourselves very close to the front of the queue for the show, so after queueing for a short while we headed in and were rewarded with really good seats very close to the front of the theatre.
“Dave Gorman’s Powerpoint Presentation” did exactly what it said on the tin: Dave Gorman stood up and did a powerpoint presentation. Of course, there was a bit more to it than that, it was basically an incredibly funny sequence of things that Dave had found interesting or amusing recently, all presented in brilliant fashion. The topic flowed from why people insist on calling him a jewish comedian, through mobile phone advertising and on to making a bit of trouble with Jim Davidson. Dave was energetic and amusing, in all it was a thoroughly brilliant hour of comedy and a great start to the festival. Also nice for it not to be ‘Dave Gorman has a wacky adventure and then tells you about it’, as he is sometimes accused of doing.
Following the show we grabbed another icy pint of beer and ‘debated’ what/where to eat. The ‘debate’ was finally settled with a rubbish but expensive slice of pizza and we headed up to the Pleasance Dome for the other show of the evening. “Arthur Smith’s Pissed Up Chat Show” was another show that did exactly what the name suggested. Arthur Smith hosts a chat show in which his guests are very drunk - certified at the beginning via a breathalyser test. Arthur himself hasn’t drunk since 2002 after almost dying from it, so it’s interesting to hear his take on booze mixed in with the drunken ramblings of his guests. Tonights guest was Julian Sands, who did a very good line in drunken recitation of Harold Pinter poems. It was another really great hour of laughing, but with a kind of serious message at its heart. It finished with a group sing song, and for some reason the lyrics were held aloft by a naked girl. Not sure how she was relevant, but that seems to be the way of things on the fringe.
Out of the gig, thinking about heading off to grab another drink, evidently having not learnt from the moral of the show, and were surprised by Walter appearing from nowhere. He was up for the weekend, and we’d suggested meeting up, but hadn’t been able to coordinate schedules enough. He’d changed plans while we were in the last show though, so we spent a nice half an hour talking to him and his friend, before parting and heading off into the night.
The final mission of the evening was simple: secure supplies for the flat. A Tesco was located and supplies were procured, we returned triumphant to make a quick bit of toast for supper. Our triumph was soon ended when we spent ten minutes trying to get the combination microwave/oven/grill to actually grill the bread before realising there was a toaster on the kitchen counter all along. Figuring that was probably a sign that the travelling all day had probably taken its toll, an end was called to proceedings. Day one at the fringe was done.
Miles travelled: at least a million
Shows: 2
Pints: 4
Meals: not enough
Naked people: 1
Despite having lived in Edinburgh for almost a year on and off while doing my MSc, I’ve never been up there at festival time. We decided to rectify this, so earlier on in the year (way earlier on in the year) we booked some accommodation for the second week of the festival and made our plans to hit the city for a festival holiday. Over a few posts I’ll describe in laborious detail what we did, what we saw, and what we (or I) thought of it. Which you’ll enjoy, I’m sure.
Getting to Edinburgh from Cardiff is pretty easy, but fairly expensive. You can fly, drive, or get the train. Flying is pretty quick, but moderately expensive. The train is pretty cheap if booked in advance, but takes a long time and if you don’t book in advance it basically requires the sale of your first born son to get a ticket. (Don’t get me started on the cost of rail travel blah blah blah). I didn’t bother to work out the cost of driving in our car; given the appalling state of it I wasn’t totally convinced it could do another trip up to Scotland and back - for sure if we were going to drive we’d need to get ‘whatever it is that makes the funny noise while braking’ fixed, plus the petrol, and we had nowhere to park up there, and there’s the whole actually having to drive 500 miles thing. After some back and forth we settled on getting the train. Luckily, because we’re the organised type (read: Lisa is organised and drags me along for the ride) we were on the ball for the advance tickets, and managed to get singles from Cardiff to Manchester for £13 each, then from Manchester to Edinburgh for £17ish each, (and the same on the way back), giving us a return cost of £60 each - pretty good.
We caught a nice early train out of Cardiff on a Sunday morning, bagged a table seat and sat back for the million hour trip to Manchester. Unfortunately for us it seemed like everyone in the world wanted to take the same train as us, by the time we got to Hereford it was rammed. A nice man (ex quality assurance chap with a nice terrier dog) took one of the seats opposite us, and he was soon joined by a skinhead Chelsea fan on his way to Stoke to watch the match. I managed to bury myself in my laptop watching a movie, leaving Lisa to make polite conversation. Ha. From what I can gather the conversation seemed to revolve around working out the price of drinks when serving at a bar. Or ‘mental arithmetic’ as it’s sometimes known. The train from Manchester was a bit better in terms of overcrowding, but not much. This time the conversation was totally football dominated. We sat by a young guy from Sunderland, who wasn’t just an avid Sunderland fan, he was an avid football fan. He seemed to know every player in every team in the whole football league, and every transfer that had occurred over summer. Usually when people ask who I support, and I reply ‘Shrewsbury Town’, there then follows a long conversation explaining what exactly that is, and inevitably there’s some explanation about how there’s a whole bunch of football going on aside from the premier league. Not with this guy - within a millisecond of the words ‘Shrewsbury Town’ leaving my mouth he was engaging me in conversation about the town players he’d played with when he was at Carlisle, where the ex-manager was now, how his son was doing, how we were looking for the new season, and on and on. Once he got going there was no stopping him. Some Scottish guys got on at Preston, and it was soon revealed that this chap’s football knowledge didn’t stop at English football - oh no, he could engage the Scots in any amount of conversation about the SPL as well. I wondered for a bit what he could do with a memory and passion like his if he applied it to something other than chasing Sunderland up and down the country and harvesting in every bit of football columnist opinion he could find. It scared me a bit, so I stopped talking to him and read my book instead. At some point I fell asleep, and when I woke up he’d gone. Probably had a five a side match to get to.
We got into Edinburgh at about 5.30pm. It was gloriously sunny and warm, and it felt good to be there. I’ve always loved the city, more than any other I’ve found myself in. Most times I’ve been there I’ve arrived by train into Waverley, so walking up out of the station felt right and a bit like coming home. It’s a strange feeling to experience in a city that you’ve spent a relatively short amount of time in, but I was genuinely excited to arrive back in Edinburgh again. Our accommodation was only a ten/fifteen minute walk from the station so we headed straight there to get checked in before our first show.
We booked accommodation in March of this year, opting for a University run studio apartment in the city centre, in the Richmond Place Apartments. Edinburgh University actually give alumni discount when booking rooms in _some_ of their halls and holiday flats, but not the ones we booked, so it came in at about £100 a night. Fairly pricey, but pretty cheap by festival standards, especially considering the location and the facilities available.
The accommodation is actually in a university halls of residence - basically it seems the university have converted a floor of a residence tower block into studio apartments. Above the apartments are six or seven floors of normal university halls. Because it was summer I guess the place was pretty empty and therefore pretty quiet, although there did seem to be some students coming and going. I can imagine in term time it must be a pretty noisy place to stay, but in summer and at festival time it’s fine. The flat itself was really nice, way better than my house; although that’s not hard to achieve. The room itself was decently sized, you could swing a cat in it for sure. It was kitted out with all mod-cons, everything one could want for a week away in Edinburgh. About here would be a good place for a picture, but I don’t have any, because I forgot to take any - if you are desperate to get an idea of what the place is like, go here and click the link for 'Richmond Place studio apartment; with mezzanine. Our room was almost exactly different from that, while being pretty much the same.
So, we checked in, threw clothes in the wardrobe, and left to go get some festival…
It’s a fairly sensible question: why do I write anything here? There aren’t going to be that many people reading, if any. Probably the only people that come past are going to be the other people in COMSC having a nose around to see what people are putting on their websites, and the few visitors I get from the random google searches that seem to appear in my analytics reports every now and again. Also probably my mum, because she’s a bit of an an internet stalker. Hi mum.
Despite the fact that no-one is reading, I think it’s important for me to write fairly regularly. It’s a good skill to practice and keep up, and I feel that even in these post-blog social network dominated days, the writing of a few lengthy blog posts on a particular topic every now and then is a fairly healthy habit to get into. The other reason to post regularly is the hope that when I post a bit of code that I’ve been working on, or an explanation of some work, someone somewhere will find it useful. So, I’ll continue to post, until I get bored.
With that in mind, recently I went back up to Edinburgh for a week for the festival. Because I have little work I feel like (or feel is ready for) writing about on here but still feel that writing semi-regularly is good for me, I’m going to post some reviews of my week up here. Almost a ‘what I did on my holidays’ type thing. So look forward to that over the next week or so.
Another update on the summer project? Already? Yes.
The project is really cracking on. We’re two weeks from the end and beginning to see the results roll in, every meeting brings a new version of the software with more functionality. Nick has successfully written a nice framework that allows us to input conversations and automatically retrieve search results based on the topics of those conversations. Even the voice input works (almost) and we’ve got enough time to try and move on to some content extraction ideas. I’ve now written a script to do some automatic evaluation and we’re in a position to subject the attendees of next week’s mobisoc meeting to a human evaluation, which I’m sure will be fun for all concerned.