Fitness Data Downloading
Like many (most?) people these days who have the foolish notion to exercise outside I track my activities with GPS and a logging app. Well, I say ‘app’, but of course with the way all things link together my data ends up shared between four or five different services.
I recently had call to download my location data for an upcoming project. One of the sites that stores my running and cycling activity is Runkeeper, and it was from here I chose to pull my data.
Runkeeper has an API, and if we’re going to pull our data out of the service the first thing we need to do is sign up to use it, which you can do at the Health Graph website. The link to sign up is buried slightly in the documentation - but you can sign up to create an app at https://runkeeper.com/partner/applications. You need to enter a few details for an application - as we’re only going to be using this for accessing our own data it doesn’t really matter what information we put in here:
Once we’ve signed up and got access to the API, we are provided with a client_id and a client_secret. These are the OAuth keys that identify our application to Runkeeper:
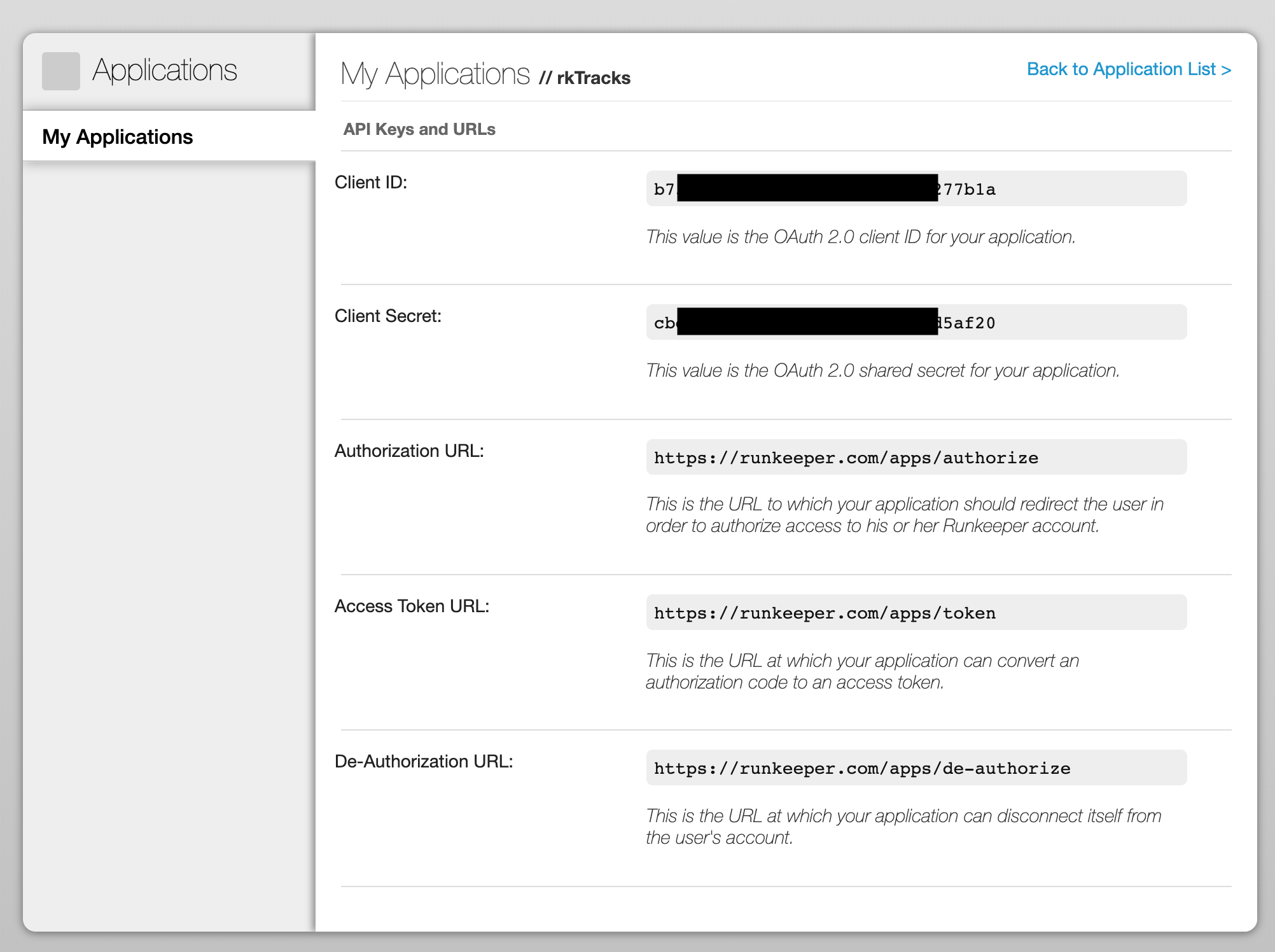
To access user data from Runkeeper we need to follow a typical OAuth flow. We open a URL, sending Runkeeper our client_id and client_secret. Runkeeper asks our user to login and give our application permission to access their data. They then send us back to our redirect address with a single use access_code. We can then make a request to Runkeeper and exchange this access_code for an access_token. This token will allow us to make requests to the Health Graph API and access the data of the user that authorised our application. If we were building a public-facing application we’d need to write a bit of server code and get it online somewhere to handle this flow, but for our purposes here we only need to authorise ourselves, so we won’t bother and we’ll do it all manually.
Putting together the first request URL is quite straightforward:
from _credentials import client_id, client_secret, access_token
DATA_DIR = os.path.join(os.getcwd(), "data")
def get_auth_url():
# create an authorisation url to copy paste into a browser window
# so we can get an access token to store in _credentials.py
base_url = "https://runkeeper.com/"
endpoint = "apps/authorize"
params = {
"response_type": "code",
"client_id": client_id,
"redirect_uri": "http://www.martinjc.com",
}
auth_url = base_url + endpoint + "?" + urlencode(params, quote_via=quote)
return auth_urlOnce we have the auth_url we can open it in a web browser. This will open the Runkeeper website and ask us to give permission to our application to access the necessary data:
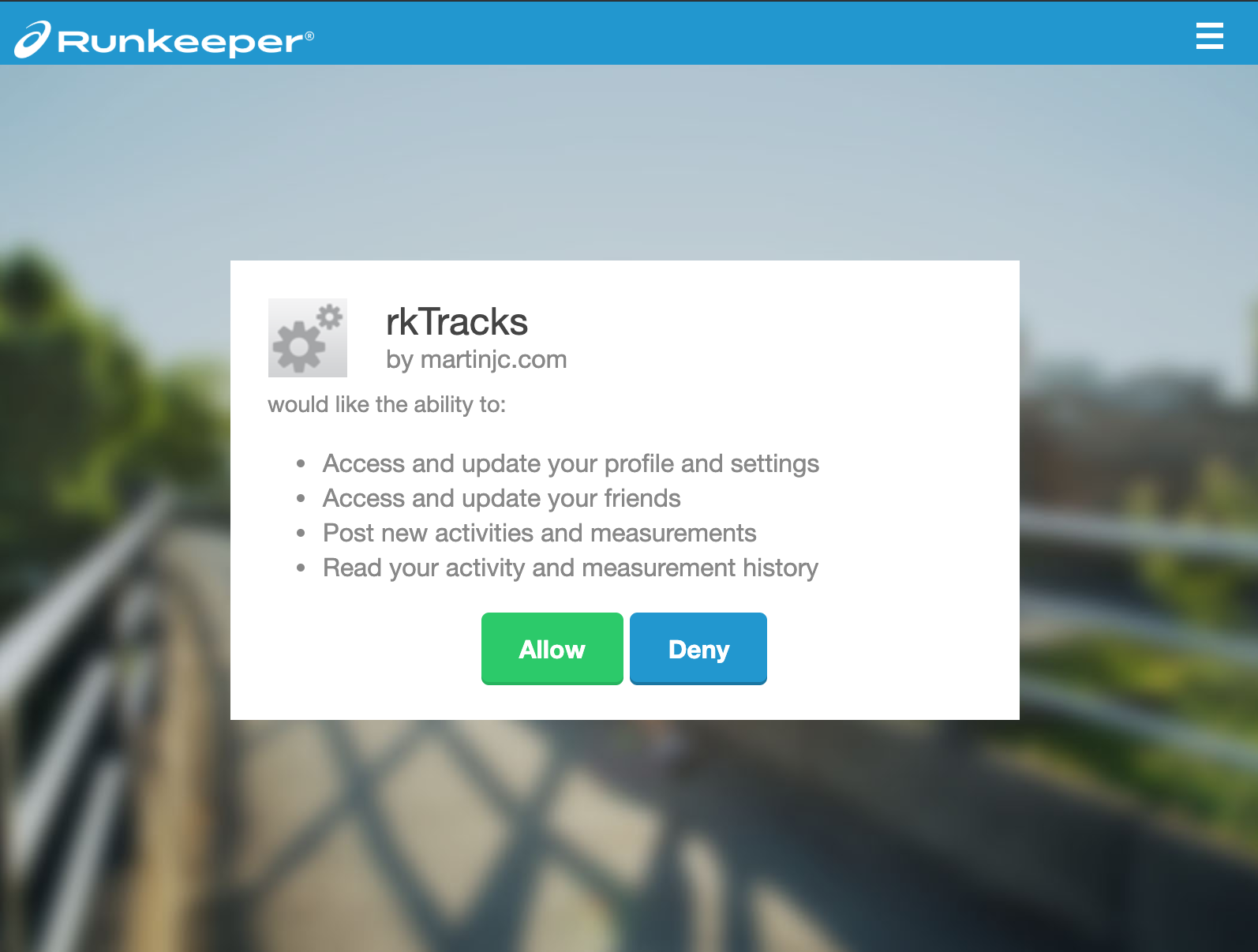
If we authorise the application, it will send us back to our redirect URL. A proper server would listen for these requests coming in, capture the code provided in the address bar and carry on with the authentication flow. Again, we’re just doing it manually, so we’ll just copy and paste that code out of the address bar so we can use it in the next step of the process:
def do_auth():
base_url = "https://runkeeper.com/"
endpoint = "apps/token"
params = {
"grant_type": "authorization_code",
"code": "CODE_WE_JUST_COPIED",
"client_id": client_id,
"client_secret": client_secret,
"redirect_uri": "http://www.martinjc.com",
}
r = requests.post(base_url + endpoint, params)
print(r.json())If all is well, the response from the server will contain the access token we need to make authenticated requests to the server.
We can then use this access_token every time we need to make a request to the API:
def get_data(endpoint, params=None):
base_url = "https://api.runkeeper.com/"
endpoint = endpoint
headers = {"Authorization": "Bearer " + access_token}
r = requests.get(base_url + endpoint, params=params, headers=headers)
if r.status_code != 200:
return None
return r.json()The above function will make a request to the given endpoint (and assuming it succeeds) will return the data back to the calling code. If we want to get the list of all activities for the user, we can use this function like so:
def get_fitness_activities():
# store activity URIs separately
with open("activities.json", "w") as activities_output_file:
activities = []
activity_data = get_data("fitnessActivities")
num_activities = activity_data["size"]
num_calls = int(num_activities / 25)
call_count = 0
if activity_data.get("items"):
activities.extend(activity_data["items"])
print(call_count, len(activity_data["items"]), len(activities))
while activity_data.get("next") and call_count < num_calls:
activity_data = get_data(activity_data["next"])
call_count += 1
if activity_data.get("items"):
activities.extend(activity_data["items"])
print(call_count, len(activity_data["items"]), len(activities))
json.dump(activities, activities_output_file)The list of activities in the Health Graph is paginated, so we need to call the endpoint repeatedly, fetching each page of activities.
Once we have downloaded the full list of activities, we can then download the full details of each activity. The API is rate-limited to 100 calls every 15 minutes per user, so we’ll put the code to sleep for 9 seconds between calls to ensure we don’t go over the rate limit:
def download_activities(activity_list):
for activity_uri in activity_list:
id_str = activity_uri.replace("/fitnessActivities/", "")
filename = os.path.join(DATA_DIR, "%s.json" % id_str)
if not os.path.exists(filename):
activity_data = get_data(activity_uri)
time.sleep(9)
if activity_data is not None:
with open(filename, "w") as output_file:
json.dump(activity_data, output_file)And that’s it. Run the code, give it enough time, and you’ll end up with all your activity data downloaded from Runkeeper. Easy.
The full code for the script is below, or in this gist here.
Next: DataJConf III
Previous: Academic Parent